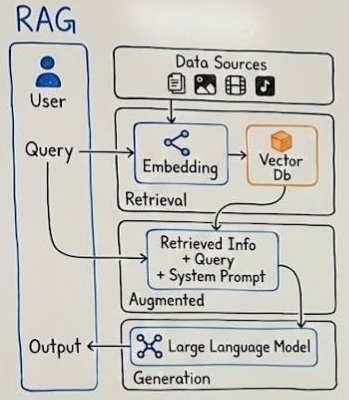
Retrieval-Augmented Generation (RAG) Architecture
Transformer Architecture
|
├─ Encoder-Only (BERT, RoBERTa)
│ └─ Embedding Models ← RAG embeddings
│ ├─ MiniLM (384 dims)
│ ├─ multi-qa-mpnet (768 dims)
│ └─ OpenAI ada-002 (1536 dims)
|
├─ Decoder-Only (GPT, Claude, LLaMA)
│ └─ Large Language Models (LLMs)
|
└─ Encoder-Decoder (T5, BART)
Text Embeddings - Cosine Similarity Calculation
similarity = 1 - cosine_distance
MODEL_NAME = "sentence-transformers/all-MiniLM-L6-v2"
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
# VECTOR_DIMENSION = 384 is fixed property of the "all-MiniLM-L6-v2" model
# Each text input will be converted into a vector with exactly 384 numbers
# ANY text - single word, a sentence, a paragraph, or a chunk of text will
# be converted into exactly 384 numbers by the model.
VECTOR_DIMENSION = 384
# Models and their dimensions
# "all-MiniLM-L6-v2" -> 384 dimensions
# "all-mpnet-base-v2" -> 768 dimensions
# "all-MiniLM-L12-v2" -> 384 dimensions
# "paraphrase-multilingual-MiniLM-L12-v2" -> 384 dimensions
Document Ingestion Techniques for Machine Learning RAG
(Retrieval-Augmented Generation)
Various techniques for ingesting documents into a Retrieval-Augmented Generation (RAG) system. RAG combines the strengths of pre-trained language models (LLMs) with the ability to retrieve relevant information from external knowledge sources. Effective document ingestion is critical for RAG system performance.
Understanding the Document Ingestion Pipeline
The ingestion pipeline typically consists of these stages:
- Loading: Retrieving documents from various sources.
- Preprocessing: Cleaning, structuring, and preparing the document text.
- Chunking: Dividing the document into smaller, manageable pieces (chunks).
- Embedding: Creating vector representations (embeddings) of each chunk.
- Indexing: Storing the embeddings and associated metadata in a vector database.
- Retrieval: Querying the vector database to find relevant chunks.
1. Document Loading Techniques
- Local File System: Simple for development and smaller datasets. Libraries like
os and glob in Python are commonly used.
- Web Scraping: Extracts data from websites. Tools include
BeautifulSoup, Scrapy (Python), and various browser automation frameworks. Careful consideration of website terms of service and robots.txt is crucial.
- Cloud Storage (AWS S3, Google Cloud Storage, Azure Blob Storage): Scalable and reliable for large datasets. Libraries provide APIs for accessing and downloading files.
- Databases (SQL, NoSQL): Direct access to data stored in databases. SQLAlchemy (Python) is a popular ORM.
- APIs: Retrieving data from external APIs (e.g., news APIs, financial data APIs).
- Document Management Systems (DMS): Systems like SharePoint, Alfresco, and Confluence often have APIs or connectors for accessing documents.
- Email Ingestion: Parsing and processing emails from inboxes.
2. Preprocessing Techniques
- Text Cleaning:
- HTML/XML Tag Removal: Stripping away markup using libraries like
BeautifulSoup.
- Special Character Removal: Removing unwanted characters (e.g., non-breaking spaces, control characters). Regular expressions are frequently used.
- Whitespace Normalization: Consolidating multiple whitespace characters into single spaces.
- Language Detection: Identifying the language of the document for appropriate processing. Libraries like
langdetect (Python) are helpful.
- OCR (Optical Character Recognition): Converting images or PDFs containing scanned text into machine-readable text. Tesseract OCR is a popular open-source option. Commercial OCR engines often offer better accuracy.
- PDF Parsing: Extracting text and metadata from PDF files. Libraries like
PyPDF2, pdfminer.six, and fitz (PyMuPDF) are widely used. fitz is generally faster and more feature-rich.
- Metadata Extraction: Extracting information like author, title, creation date, and modification date. Metadata can be crucial for filtering and ranking retrieved chunks.
Chunking is arguably the most critical aspect of document ingestion. The size and nature of chunks dramatically affect retrieval performance.
- Fixed-Size Chunking: Splitting the document into chunks of a predetermined length (e.g., 512 tokens). Simple but often disrupts context.
- Recursive Character Splitting: Splitting by sentences, paragraphs, or sections. Aims to preserve semantic boundaries. Requires logic to handle edge cases (e.g., sentences spanning across sections).
- Token-Based Chunking: Using a tokenizer (e.g., the tokenizer used by the LLM) to split the document into chunks that respect token boundaries. Ensures that chunks are compatible with the LLM's input limits. Libraries like
tiktoken (OpenAI) are used.
- Context-Aware Chunking: Combining techniques to preserve document structure. For example, splitting by section headings and then further dividing sections into smaller chunks.
- Semantic Chunking: Attempts to group sentences or paragraphs with related meaning together. Can involve techniques like clustering or topic modeling, which are computationally intensive.
- Overlapping Chunks: Creating chunks that have some overlap to maintain context across chunk boundaries. Useful when context spans chunk boundaries.
4. Embedding Techniques
- Sentence Transformers: Models like
all-MiniLM-L6-v2 offer a good balance of speed and accuracy. Widely used for creating embeddings for RAG.
- OpenAI Embeddings: Accessible through the OpenAI API. Provide high-quality embeddings, but incur costs.
- Hugging Face Transformers: Allows access to a vast range of embedding models.
- FAISS (Facebook AI Similarity Search): A library for efficient similarity search, often used in conjunction with embedding models.
- Annoy (Approximate Nearest Neighbors Oh Yeah): Another library for approximate nearest neighbor search.
5. Vector Databases
Vector databases store and index embeddings for efficient retrieval.
- Pinecone: A managed vector database service. Offers high performance and scalability.
- Weaviate: An open-source vector database with GraphQL API and a focus on semantic search.
- ChromaDB: An in-memory vector database suitable for development and smaller projects.
- Milvus: An open-source vector database designed for large-scale similarity search.
- Qdrant: An open-source vector database with filtering and other advanced features.
- FAISS (used in conjunction with other databases): Can be used as a standalone index but is often integrated into other solutions.
6. Advanced Considerations
- Metadata Filtering: Storing and querying metadata alongside embeddings to filter results (e.g., search for documents created within a specific date range).
- Reranking: Using a separate model to rerank retrieved chunks based on relevance to the query. Improves the precision of retrieved results.
- Hybrid Search: Combining vector search with traditional keyword search to leverage the strengths of both approaches.
- Dynamic Chunking: Adjusting chunk size dynamically based on document content and query patterns.
- Knowledge Graph Integration: Incorporating knowledge graph information to enhance search and context.
- Long Context Handling: Techniques for dealing with very long documents, which may exceed the context window of the LLM and vector database. These include summarization, hierarchical chunking and windowed retrieval.
- Evaluation and Monitoring: Regularly evaluating the RAG system’s retrieval performance (e.g., using metrics like recall and precision) and monitoring the ingestion pipeline for errors.
RAG end-to-end workflow
This diagram illustrates the end-to-end workflow of a Retrieval-Augmented
Generation (RAG) system. A user submits a query, which is converted into
embeddings and used to retrieve relevant information from external data sources
stored in a vector database. The retrieved context is combined with the
original query and a system prompt to form an augmented input. This enriched
input is then passed to a large language model, which generates a more
accurate, grounded, and context-aware response as the final output.