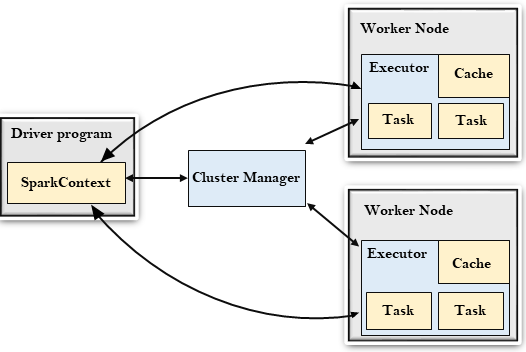
A unified analytics engine designed for large-scale data processing. It provides an interface for programming clusters with data parallelism and fault tolerance.
collect or save) is triggered.Basic data structure with operations like map, filter, and reduce. Provides fault tolerance through lineage.
High-level data structure optimized for querying, backed by Catalyst optimizer. Supports SQL queries, making it a preferred choice for structured data.
Type-safe, object-oriented API available in languages like Scala. Offers benefits of both RDDs and DataFrames but is limited in Python.
Examples: map, filter, flatMap, union, groupByKey. These are lazy operations that produce new RDDs but don’t execute until an action is called.
Examples: collect, count, reduce, saveAsTextFile. Actions trigger the execution of transformations and return results to the driver.
Catalyst Optimizer (for SQL and DataFrames): Uses rule-based and cost-based optimization to produce efficient query plans.
Memory Management: Manages caching, shuffle files, and resource allocation for performance.